序言
继去年发布graviton2之后,今年aws如期发布了graviton3。graviton3在aws数据中心的落地标志着其在自研芯片的道路上又成功的迈进了一大步,同时也标志着其在公有云上的护城河又一次得到了加宽。
aws graviton芯片生态打造
在分析graviton3之前,我们先来看一下aws 在打造graviton生态方面都取得了哪些成果 - 基于graviton aws推出一系列实例,覆盖到存储,数据库,计算,大数据分析 - 计算密集型:c6g, c6gd, c6gn - 内存密集型:r6g, r6gd, x2gd - 存储密集型:lm4gn, ls4gn - GPU实例:g5g - 操作系统兼容 - cetos, redhat, debian, fedora, freebsd, ubuntu, netbsd, suse
- containers
- aws fargate, aws EKS, docker, k8s
- 第三方合作伙伴
- NVIDIA HPC sdk available in 2022
- SAPHANA
大胆预测,未来aws在自己的数据中心内,大部分的服务器以及硬件都可能是自研的。理由也比较简单,一个是可控,一个是成本优势比如aws推出的nitro ssd 直接跟flash memory厂商合作省去了中间商的差价。另外一个最重要的是,未来云厂商的护城河有多宽取决于云厂商自研硬件的能力。同时相对于传统服务器厂商,云厂商能够根据自己客户的业务痛点以及相关的性能瓶颈做有针对性的优化,而这个优势像intel, AMD这种厂商是完全没有的。
graviton3架构
- cpu:ARM V1, 64core, 2.6GHZ
- 内存:8 channel DDR5,内存全加密设计, 内存带宽300GB/s
- 晶体管:550亿
- I/O:2 * PCIe gen5
- 设计工艺:chiplet, 7 silicon die, 5nm
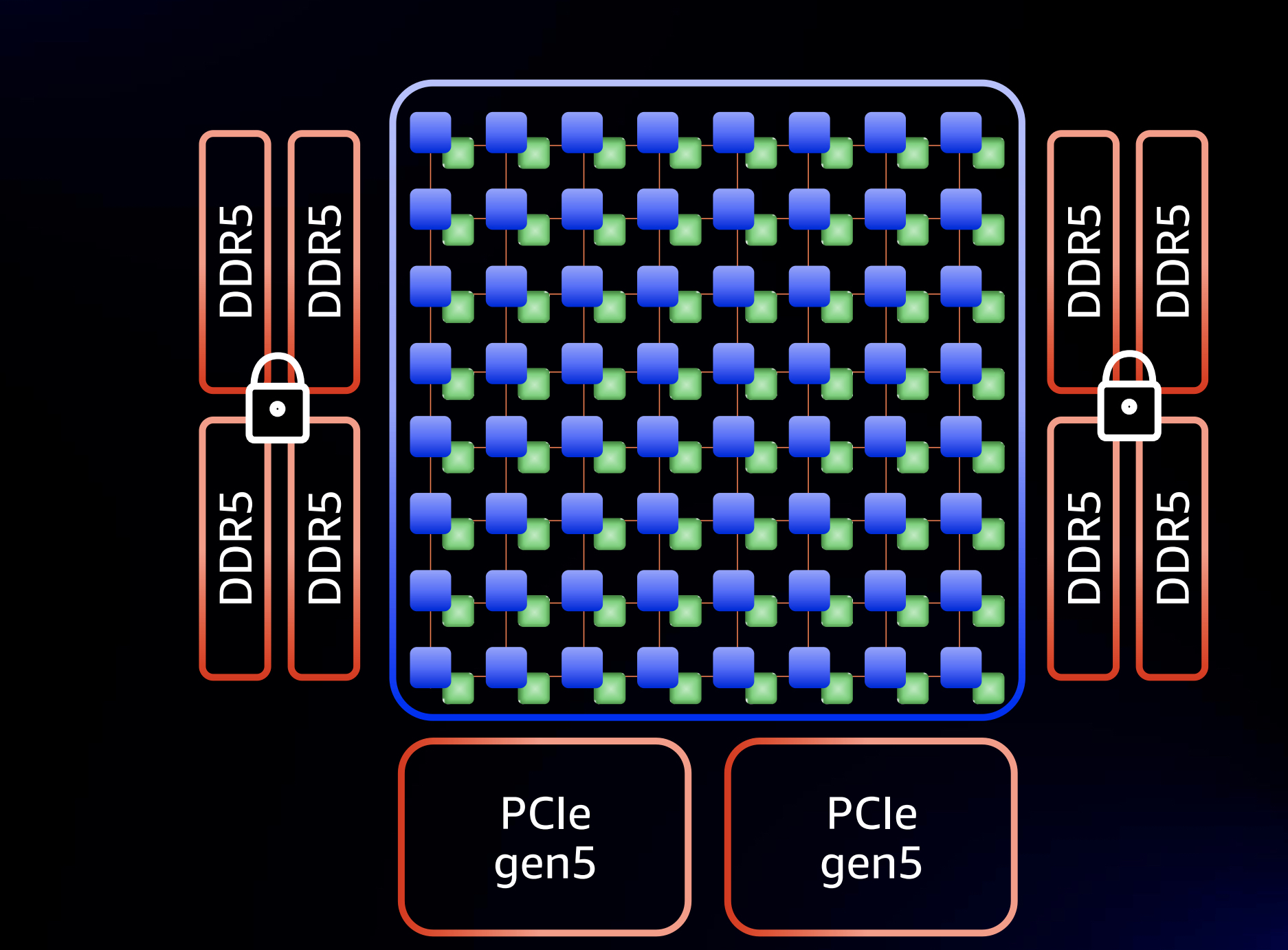
如上图所示,64 core占用了一个die, 其余的分别是2个die for pcie gen5, 4个die for DDR5 mem controller。
基于graviton3,aws发布了c7g服务器如下图所示:

c7g服务器架构如下: * no numa架构,无SMT,每个vcpu都是一个physical core * 3 sockets/server, 采用一个Nitro card 带3 个graviton 3 sockets, 将传统42U 机架利用率提高50%的同时,也顺便降低了功耗。 * 8 channel DDR5
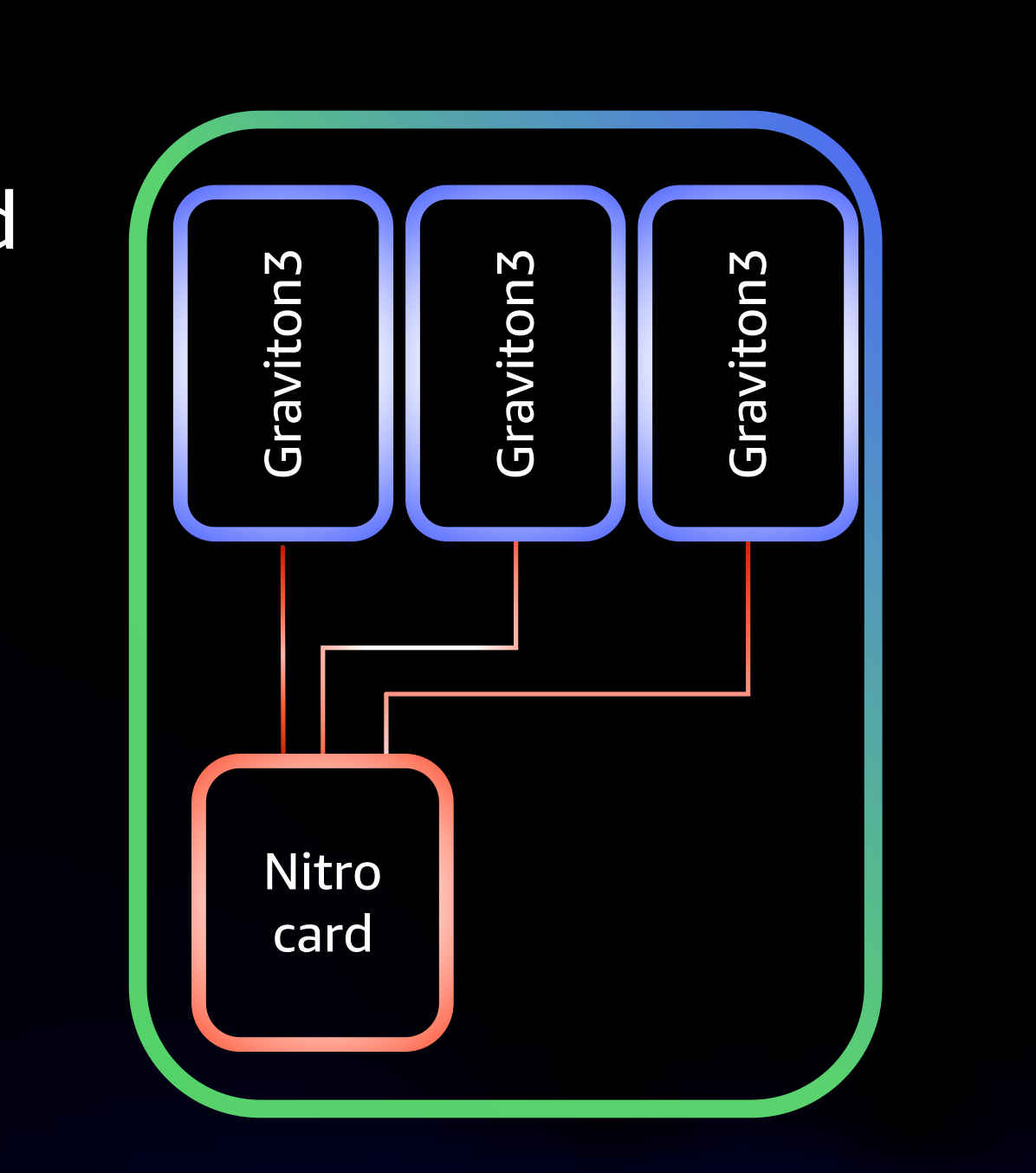
关于这个一带三架构这里我详细介绍一下,这里的每个sockets其实都一个单路的graviton3服务器。底层实现原理其实也比较简单,每台单路的服务器通过物理link直接跟nitro 卡链接,然后这个link主要是用来传输标准的pcie 协议,使得nitro card能为三台服务器模拟设备。
其实这种设计并不是aws首创,国外的dpu创业公司fungible 很早就提出了这种设计,只是aws 成功的把这种设计在其数据中心进行了落地。
graviton3 背后的设计逻辑
1.gravition3 只提供64 cores,2.6GHZ
大多数人认为如果要提升 workload的performance,天然就会想到增加服务器cpu的数量以及提升cpu 运行频率。确实,大多数服务器厂商也都是这么做的。比如,不管是intel还是amd都在疯狂的堆core和提高频率,这一点可以从这两家下一代的服务器架构上看出一些端倪。intel的下一代SPR平台最大56C(112HT), 而AMD下一代平台Genoa达到了96C(192HT),而两者的cpu 运行频率基本都是3.0GHZ以上。
但是,随着Dennard scaling 定律的失效,当你提升频率的同时cpu功耗也在不断的提高。站在aws角度来看,这并不是他们想要的,他们希望在performance和功耗之间找到一种平衡。那么graviton3是怎么做的呢?答案就是他们把core 做的更wider,也就是说让每个cpu cycle内做更多的工作。
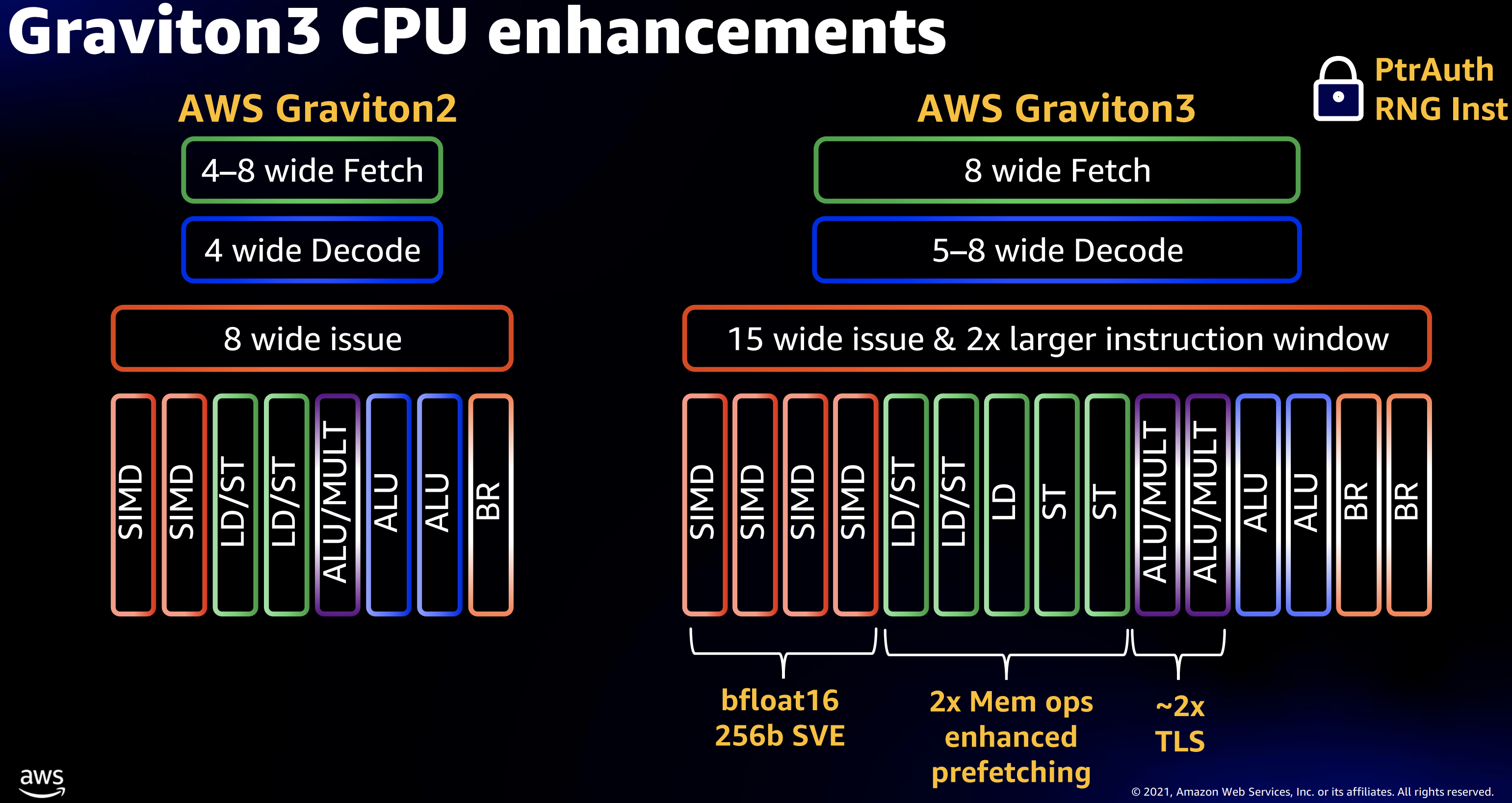
graviton3 cpu 增强部分如图2所示,具体优化如下:
- 取指(Fetch), 译码(decode),执行(issue, instruction window) 性能翻倍
前两个大家都比较熟悉,这里主要解释一下issue instruction window, 这个窗口大小决定了一个cpu cycle内可以选取多少已经ready的指令来进行执行。窗口越大那么就可以选取越多的指认来执行(这些指令之间是无依赖的)。但是这个窗口大小是受限于cycle time的,也就是说不能无限放大。
- 支持bfloat 16, 256b SVE(可扩展矢量指令Scalable Vector Extension,主要针对HPC,机器学习场景)
- 两倍的mem ops的增强
- 两倍的TLS性能
2.graviton3 不支持numa
numa架构大家都很熟悉了,它主是为了解决SMP即对称多处理器架构下,随着cpu的增多而产生的内部访问瓶颈。做过性能优化的同学应该都了解,在像graviton这种ARM架构下跨numa访问内存导致的性能衰减在某些业务场景下可达到50%,而云上业务如果要做业务优化都必须要case by case的分析,尤其是像aws这种超大规模云厂商的场景下,这种优化策略基本上不可行。因此,graviton系列干脆从一开始就不支持numa架构。那么怎么解决这个内存访问的问题呢,aws一方面保持核的数量不会太多graviton系列都是64核,另一方面增加内存带宽比如gravion3直接上DDR5,当然上DDR5不仅仅是为了解决这个问题,后面会再聊到这个话题。所以,可以预见后面其他大云厂商也都会紧跟aws脚步陆续推出无numa的 ARM server。
3.PCIe gen5 and DDR5 一次给你上齐
这一点上可能大家都没有想到,这些新的硬件会在AWS 这种云厂商在自研的ARM服务器上提前release出来。其他的硬件服务器厂商基本上都要到2022年才能提供,比如intel SPR以及AMD 的Genoa。其实仔细想想也可以理解,aws这种云厂商主要是有业务驱动的,而其他的硬件厂商都是面向技术驱动的。当然还有一点就是开篇所提到的,graviton3得益于chiplet的设计工艺,使得它能更加快速的推向市场。
刚才提到了aws是面向业务的芯片设计,在设计graviton3的时候也确实考虑了真实的业务场景。比如现在的很多业务只要你给他更多的内存带宽和更低的内存访问延时他就能跑的很“开心”,因此这也是graviton3上ddr5原因之一。
另外,graviton3未来面向的场景更多的是HPC和机器学习,这些更多的是以hpc集群或者机器学习集群呈现给用户。这些场景的特点一是东西向node之间interconnect带宽要求很高,另一方面就是这些业务都是吃内存的主。
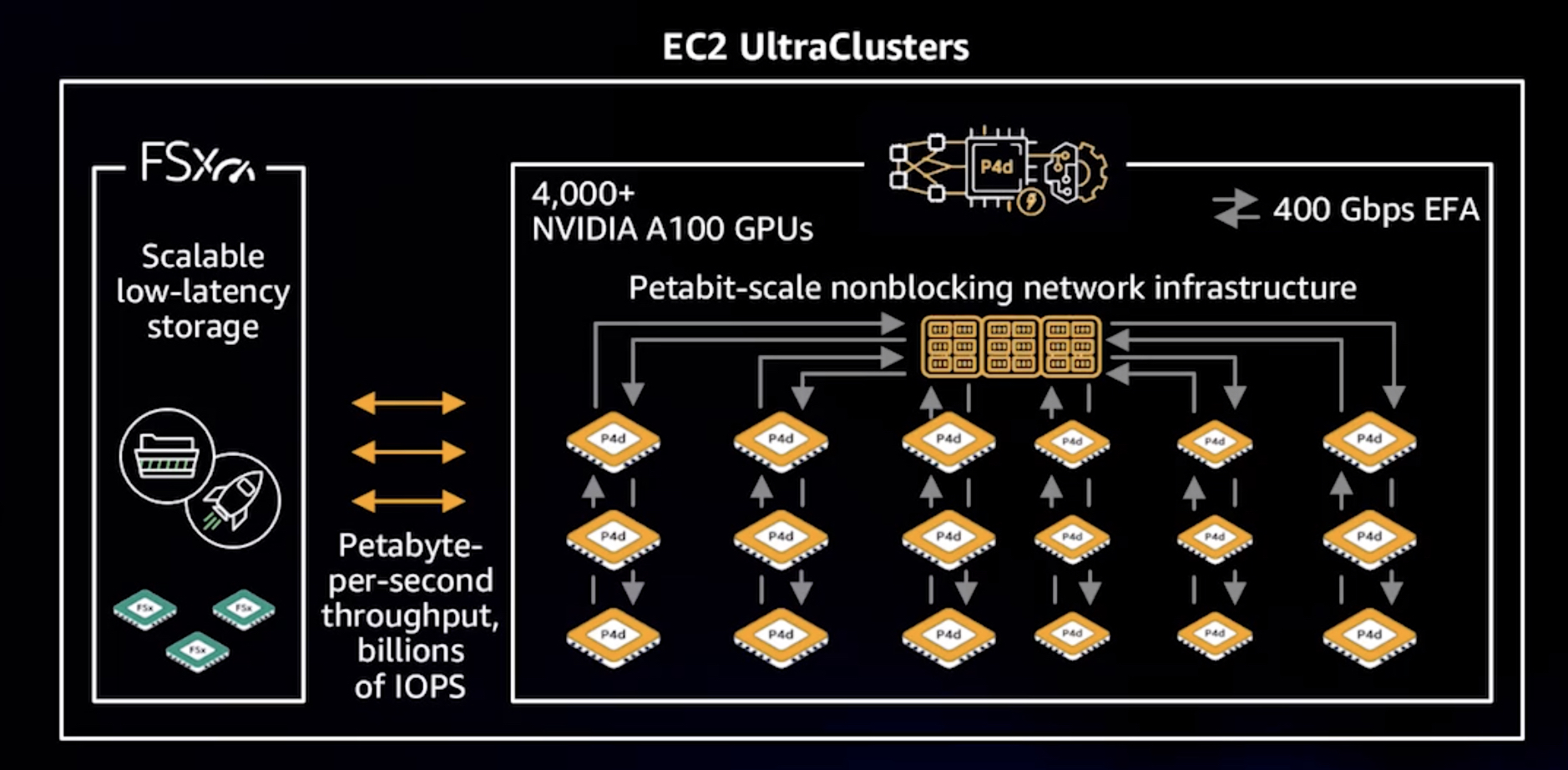
上图是一张aws的HPC超算集群图,从图中可以看到东西向连接带宽已经达到400Gbps,考虑到后面的扩展需求,上pcie gen5就顺理成章了。另外,除了pcie链路的压力,这种高带宽对memory 带宽也同样有压力。不管是RDMA还是DMA,最终都是要跟memory controller打交道,如果你的内存带宽达不到,你使用性能再高的pcie链路也是不行的。
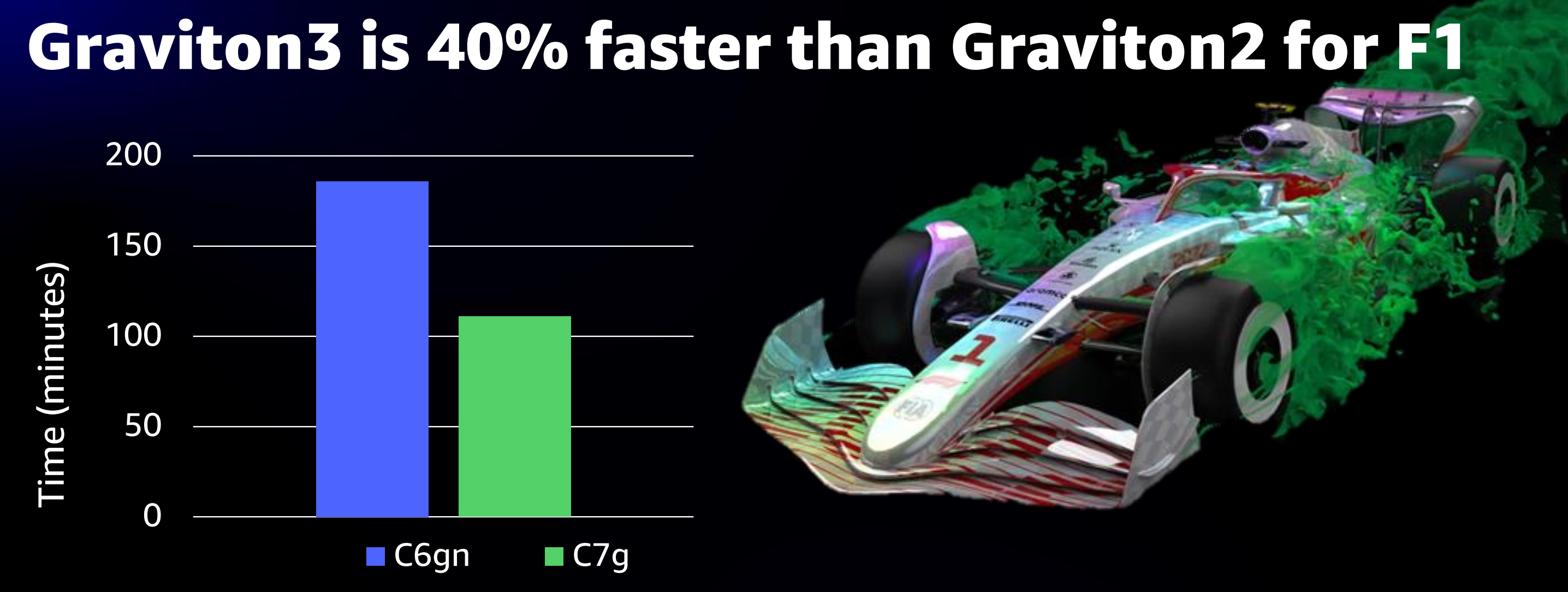
4.性能测试